원본 사과게임과의 난이도 차이
2026년 3월 13일
요약
원본 사과게임(フルーツボックス)에서 보드 500개를 스크린샷과 OCR로 추출한 뒤, 생성 알고리즘이 어떻게 돌아가는지 통계적으로 분석해봤다. 총 85,000개의 숫자를 확인한 결과, 각각의 칸은 1~9 사이에서 독립적으로 균등하게 뽑히고, 위치 편향이나 인접 칸 상관, 특정 숫자 쏠림 같은 패턴은 보이지 않았다. 또한 한 보드의 모든 숫자 전체합은 보드마다 달랐으며, 모두 10의 배수임을 확인할 수 있었다. 이를 통해 우리는 우리가 오마주한 원본 사과게임이 Rejection Sampling으로 보드를 생성한다고 추정했고, 이를 구현해서 생성한 보드는 KS 검정 결과 원본 데이터와 유의미한 차이가 없었다 (p=0.65).
한줄 요약: 우리 사과게임의 보드 난이도는 원본 사과게임과 같다.
1. 서론
사과게임(フルーツボックス)은 17×10 격자에 1~9 숫자가 깔리고, 합이 10이 되는 직사각형 영역을 골라 지우는 퍼즐 게임이다. 간단하지만 중독성 있는 이 게임을 수 백 판씩 하다 보면, 이 게임의 난이도는 매 판 달라지며 보드의 숫자 분포에 따라 결정된다는 것을 알게 된다. 주로 큰 숫자가 많을수록 어려울 확률이 높고, 어떤 경우는 최적에 가까운 풀이법으로도 매우 낮은 점수밖에 얻지 못한다.
극단적으로 생각해보면 이렇다.
- 170칸이 전부 9라면 총합은 1,530이지만, 어떤 조합으로도 합 10을 만들 수 없어서 점수는 0점
- 반대로 전부 1이라면 총합은 170이고, 아무 10칸만 골라도 합이 10이 되니 거의 만점에 가까운 판
실제 보드는 물론 이 둘 사이 어딘가에 있다. 그래도 큰 숫자(7, 8, 9)가 많으면 확실히 빡빡하고, 낮은 숫자가 많으면 상대적으로 조합을 만들기가 쉬워진다. 일정 수준 이상의 플레이어라면 제한시간이 끝난 시점에 '보이는' 숫자쌍은 거의 찾게 되므로, 보드의 숫자가 얼마나 잘 나오는지가 점수를 결정하는데 큰 역할을 한다.
파생 게임 중에는 이걸 "불공평하다"고 보고 숫자 분포를 일부러 조정하는 경우도 있다. 하지만 나는 오히려 이 운 요소가 원작의 핵심 재미라고 생각한다. 매 판 난이도가 조금씩 다르기 때문에 긴장감이 생기고, 난이도에 따라 전략도 다양해진다. 특히나 대결을 하는 경우에 이러한 보드 운 요소가 큰 재미 요소가 되는데, 누군가는 좋은 보드에서 최고의 득점을 내고, 누군가는 좋지 않은 보드에서 최대한의 점수를 내기 때문에 승부가 더 예측불가능해지고 흥미진진해진다.
다만 원본의 게임으로는 같은 보드로 게임하는 것이 불가능하고, 때문에 N판의 평균을 가지고 대결을 한다던가 하는 방식으로 대결할 수밖에 없었다. N이 충분히 크지 않기 때문에 가끔은 불쾌할 정도로 운의 요소가 너무 커질 때가 있었고, 그래서 같은 보드로 함께 플레이할 수 있는 이 게임을 만들게 되었다. 원본처럼 보드의 난이도가 매 판 바뀌는 점은 유지하면서도, 같은 보드로 플레이하므로 '보드의 난이도를 고려한 전략' 또한 게임의 일부가 되도록 하고 싶었다.
따라서 "원본과 최대한 같은 난이도 분포를 재현하는 것"은 중요했다. 더 어렵지도 쉽지도 않게. 그래서 원본 게임에서 500개의 보드를 모아서 어떤 방식으로 생성되는지 분석해봤다.
2. 방법
2.1 보드 수집
Playwright(headless Chromium, 2× 해상도)를 써서 원본 사이트 플레이를 자동화했다.
접속 → Play → 스크린샷 → 새로고침
이 과정을 500번 반복해서 보드 이미지를 모았다.
2.2 OCR 파이프라인
스크린샷에서 숫자를 읽는 과정은 다음 순서로 진행했다.
1. 녹색 테두리 감지 — HSV 임계값으로 게임 프레임을 찾는다.

Figure 1. 녹색 테두리 감지 결과
2. 사과 영역 crop — 빨간색 HSV 마스크를 이용해 사과 영역만 잘라낸다.

Figure 2. 사과 영역만 crop한 결과
3. 격자 정렬 — centroid와 1D 클러스터링으로 10행 × 17열 격자를 맞춘다.

Figure 3. 격자 정렬 (노란선: 행/열 중심, 초록점: 각 칸 중심)
4. 칸별 OCR — 각 60×60 px 칸을 전처리한 뒤 Tesseract로 숫자를 읽는다.
사용한 전처리:
- Margin crop (상 17, 하 10, 좌우 19 px)
- Grayscale → threshold 200 → invert
- Pad 15px → resize 128×128 → threshold 128
- Tesseract
--psm 6 --oem 1 -c tessedit_char_whitelist=123456789

60×60 cell→

Crop→

Gray→
Thresh→
Invert→

Final→7

60×60 cell→

Crop→

Gray→

Thresh→
Invert→

Final→9

60×60 cell→

Crop→

Gray→
Thresh→
Invert→

Final→8
Figure 4. 칸별 OCR 전처리 예시
2.3 데이터 무결성 검증
2.3.1 체크섬 검증
각 보드는 170개 숫자($d_i \in \{1, \dots, 9\}$)로 구성되고, 게임 규칙상 합이 10의 배수여야 한다.
$$\sum_{i=1}^{170} d_i \equiv 0 \pmod{10}$$즉, OCR이 틀렸다면 이 조건을 깨뜨릴 가능성이 높다. 오류가 무작위 치환이라고 보면, 틀렸는데도 우연히 체크섬을 통과할 확률은 대략 1/10 정도다.
$$P_{\text{false\_pass}} \approx \frac{1}{10}$$결과적으로 500개 보드 전부 체크섬 통과.
2.3.2 수동 검증
여러 오류가 서로 상쇄되어 체크섬을 우연히 통과하는 경우를 잡기 위해, 전체의 5%인 25개 보드를 직접 스크린샷과 대조해봤다. 눈으로 검사한 숫자는 총 4,250자리(170 × 25)였고, 오류는 0건이었다.
$n$번 검사에서 오류가 하나도 안 나왔을 때, 오류율 $p$의 95% 신뢰 상한은 Rule of Three로 다음처럼 잡을 수 있다.
$$p \le \frac{3}{n} = \frac{3}{25} = 0.12 \quad (12\%)$$2.3.3 종합 신뢰도
두 검증 방법은 독립적이고, 따라서 미검출 오류의 결합 확률은 다음과 같다.
$$P_{\text{undetected}} = p \times P_{\text{false\_pass}} \approx 0.12 \times 0.1 = 0.012 \quad (1.2\%)$$즉, 데이터셋의 통계적 신뢰도는 98.8%로, OCR 처리가 잘 되었다고 볼 수 있다.
3. 실제로 어떤 패턴이 보였나
3.1 숫자 빈도는 거의 완벽하게 균등했다
500판, 총 85,000개 숫자를 세어보니 1~9는 거의 똑같은 비율로 나왔다.
| 숫자 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 횟수 | 9,479 | 9,381 | 9,373 | 9,422 | 9,371 | 9,562 | 9,512 | 9,319 | 9,581 |
| % | 11.15 | 11.04 | 11.03 | 11.08 | 11.02 | 11.25 | 11.19 | 10.96 | 11.27 |
| 균등분포 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 |
카이제곱 검정 결과도 χ² = 7.30, p = 0.504로 나왔다. 즉, "각 숫자가 같은 확률로 나온다"는 가설을 전혀 기각할 수 없었다.
이건 꽤 중요하다. 적어도 전체 숫자 분포를 일부러 조정하는 흔적은 보이지 않는다는 뜻이기 때문이다.
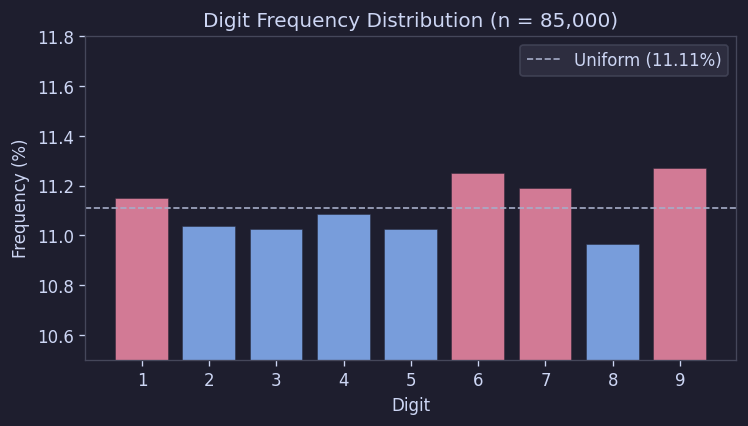
Figure 5. 숫자별 출현 빈도
3.2 보드 총합도 이론값과 잘 맞았다
만약 170칸을 1~9 균등분포에서 독립적으로 뽑는다면, 보드 총합의 이론적 평균은 850이고 표준편차는 약 33.7이다.
실제 관측값은 평균 851.3, 표준편차 34.8이었다.
이 정도면 사실상 이론과 거의 같은 수준이다. 즉, 총합 분포만 봐도 "기본적으로는 균등 난수 170개를 뽑고 있다"는 해석과 잘 맞는다.
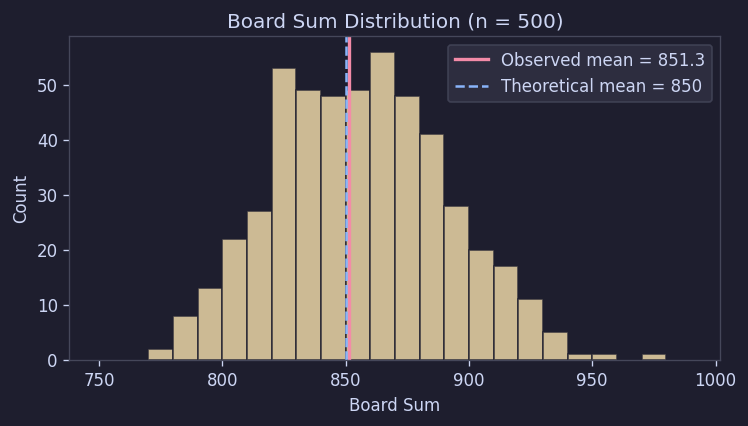
Figure 6. 보드 총합 분포
3.3 특정 위치에 특정 숫자가 몰리지는 않았다
혹시 어떤 위치에는 큰 숫자가 더 자주 나온다거나, 가장자리와 중앙이 다르다거나 하는 규칙이 있을 수도 있다. 그래서 칸별 평균값을 확인해봤다.
결과는 아주 단순했다. 500판 평균 기준으로 모든 칸이 거의 5.0 근처에 모였고, 행 평균은 [4.97, 5.04], 열 평균은 [4.92, 5.07] 범위였다.
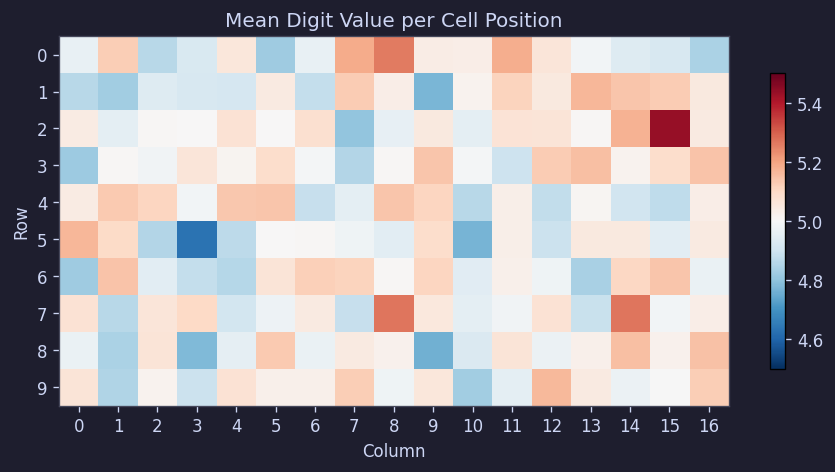
Figure 7. 칸별 평균 숫자 히트맵
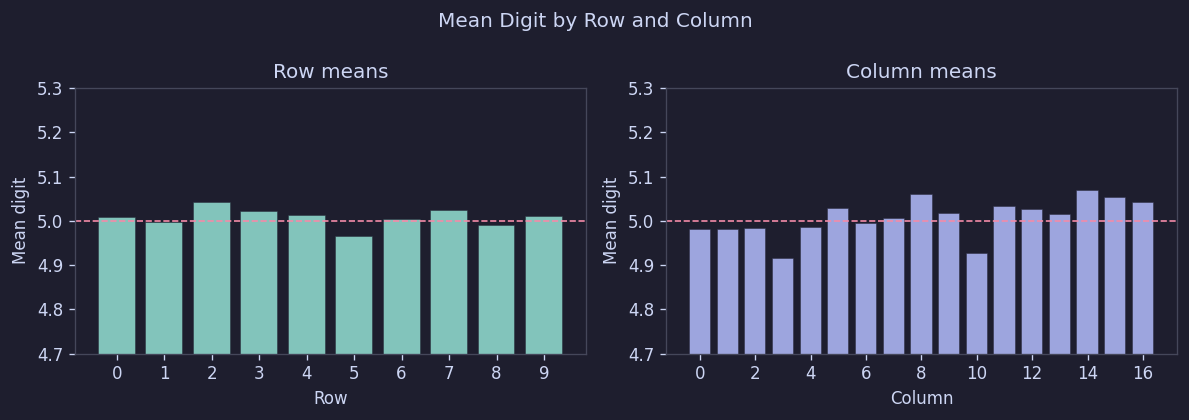
Figure 8. 행/열별 평균 숫자
즉, 위치별 편향은 보이지 않았다. 적어도 "윗줄은 쉽게 나오게 한다", "가운데에 큰 수를 더 깐다" 같은 구조는 없는 셈이다.
3.4 전체는 균등하지만, 개별 판은 꽤 들쭉날쭉하다
여기서 재미있는 건, 전체적으로는 완전히 균등해 보여도 개별 보드 단위로 보면 꽤 불균형한 판이 많이 나온다는 점이다. 어떤 판은 9가 유난히 많고, 어떤 판은 1이나 2가 상대적으로 많이 나온다. 플레이할 때 느끼는 "이번 판 왜 이렇게 어렵냐"가 실제로 데이터에서도 보인다는 뜻이다.
이걸 수치로 보기 위해 각 보드의 숫자 구성과 기대값(각 숫자당 18.89개)을 비교해 카이제곱 값을 계산했다. 독립 균등분포라면 이 값은 χ²(df = 8)을 따라야 한다.
| 관측값 (500) | Rejection Sampling (10,000 sim) | χ²(df=8) 이론값 | |
|---|---|---|---|
| 평균 | 8.22 | 7.99 | 8.00 |
| 중앙값 | 7.46 | 7.35 | 6.34 |
| 표준편차 | 4.17 | 3.94 | 4.00 |
관측값은 이론값과 꽤 잘 맞았고, 시뮬레이션 결과와도 거의 겹쳤다. 즉, "개별 판이 들쭉날쭉한 것" 자체가 오히려 자연스러운 현상이다. 누군가 의도적으로 난이도를 조정한 흔적이 아니라, 원래 무작위 생성이면 당연히 나와야 하는 변동성에 가깝다.
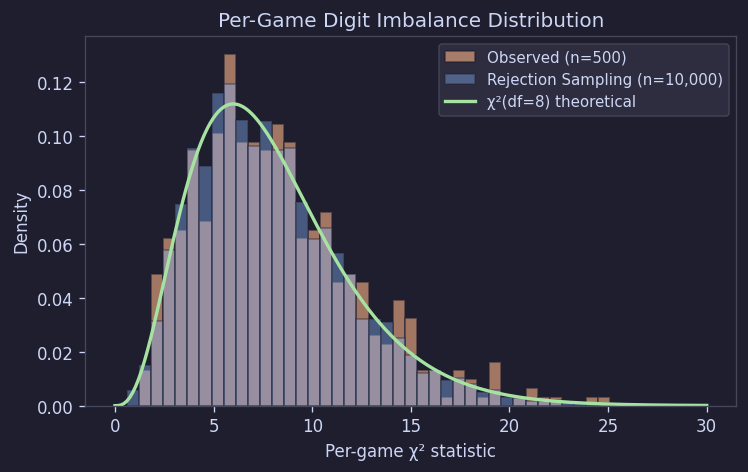
Figure 9. 판별 카이제곱 분포 (관측 vs 시뮬레이션 vs 이론)
Q-Q 플롯으로도 확인할 수 있다:
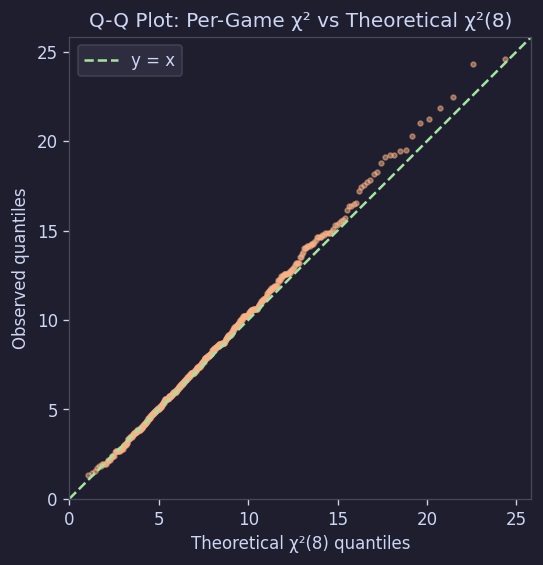
Figure 10. Q-Q 플롯: 판별 χ² vs 이론적 χ²(8)
최대 편차와 부족/과잉 패턴
각 보드에서 기대값에서 가장 많이 벗어난 숫자의 편차를 봐도 시뮬레이션과 잘 맞았다:
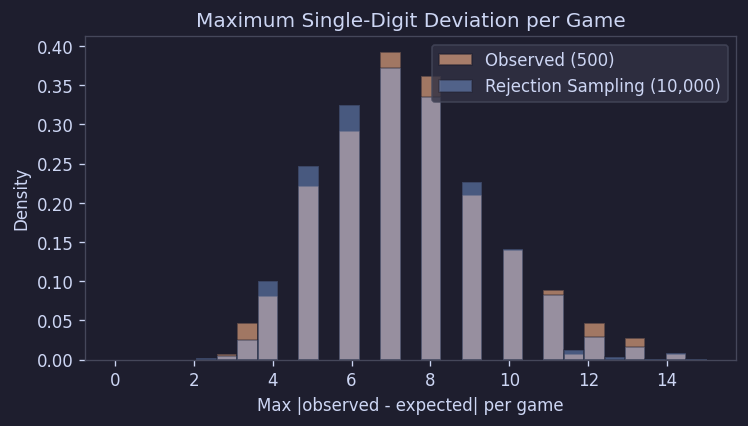
Figure 11. 판별 최대 편차 분포
"가장 많이 나온 숫자"나 "가장 적게 나온 숫자"를 세어봤을 때도 특정 숫자에 쏠림은 없었다:
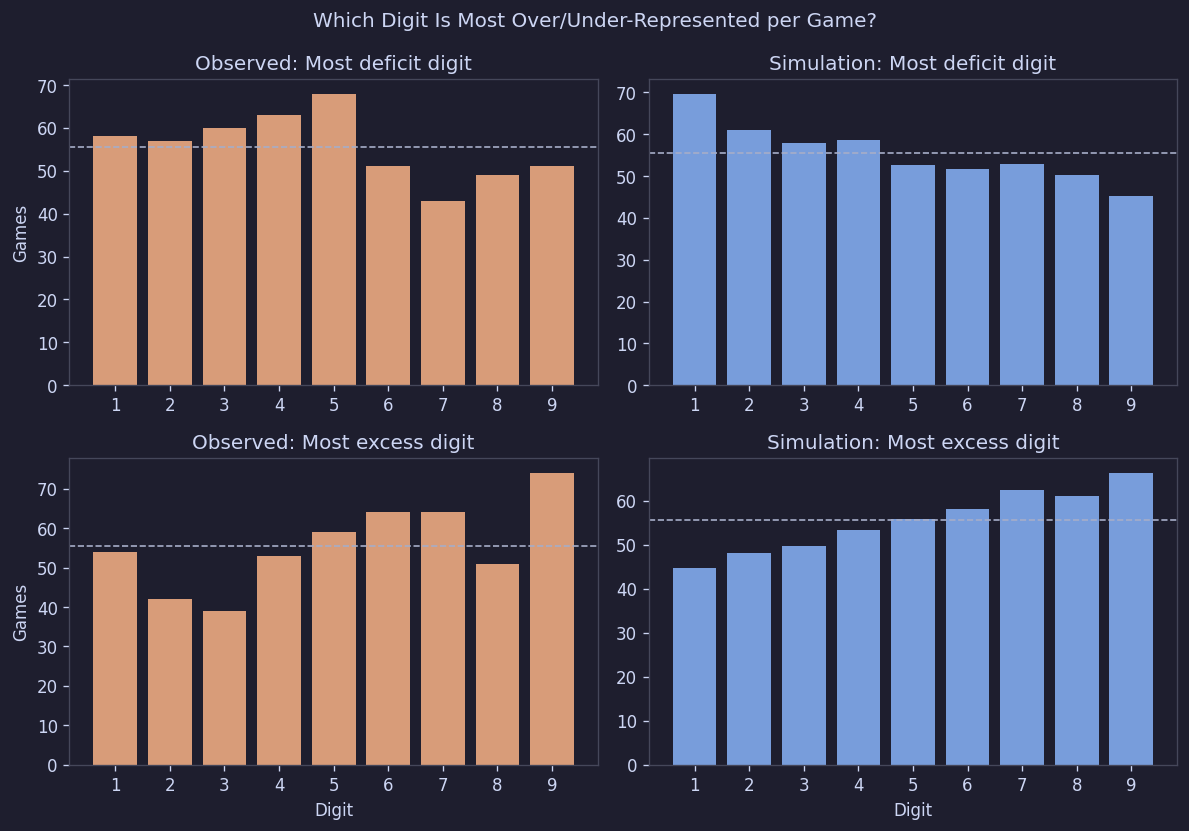
Figure 12. 판별 부족/과잉 숫자 패턴
쉽게 말해, 어떤 숫자가 자주 과잉되거나 자주 부족해지는 구조는 없었다.
3.5 인접 칸끼리도 사실상 독립이었다
혹시 숫자가 완전히 독립이 아니라, 옆칸과 어느 정도 연관되어 있을 수도 있다. 예를 들어 비슷한 숫자끼리 뭉친다든가, 작은 수 다음엔 큰 수가 나온다든가 하는 식이다.
그래서 인접 칸 상관을 계산해봤다.
| 방향 | n | Pearson r | p-value |
|---|---|---|---|
| 가로 | 80,000 | 0.0007 | 0.853 |
| 세로 | 76,500 | -0.0012 | 0.730 |
결과는 둘 다 거의 0이었다.
전이 행렬(숫자 i 다음에 j가 나올 확률)도 기대값 11.1%에서 ±0.5%p 안쪽이었고:
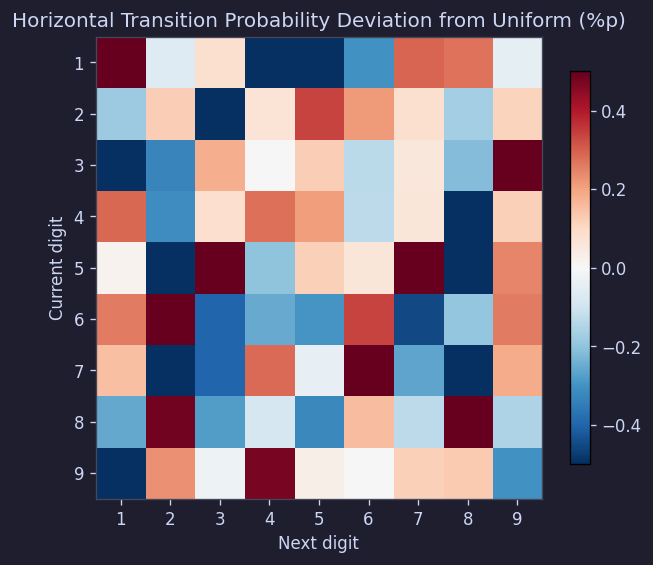
Figure 13. 수평 전이 확률 편차 행렬
자기상관도 전 시차에서 95% 신뢰구간 안에 들어왔다:
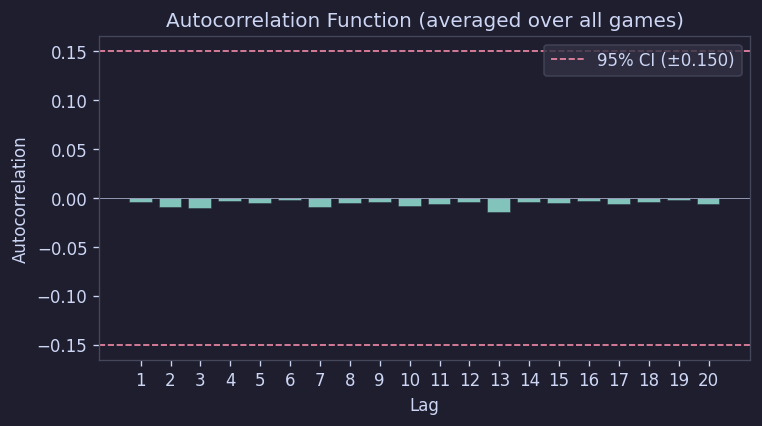
Figure 14. 자기상관 함수
즉, 숫자들은 이웃한 칸과도 특별한 관계 없이 깔린다고 보는 편이 맞다.
4. 그래서 생성 알고리즘은 뭘까
지금까지 나온 결과를 정리하면 이렇다.
- 각 칸의 숫자는 1~9 사이에서 균등하게 나온다
- 칸들 사이에 특별한 상관은 없다
- 위치 편향도 없다
- 다만 전체 합은 반드시 10의 배수여야 한다
이 조건을 가장 단순하게 만족하는 방법은 사실 하나다. 바로 rejection sampling이다.
즉,
- 일단 170칸에 숫자를 전부 랜덤으로 채운다
- 합을 계산한다
- 합이 10의 배수면 채택한다
- 아니면 버리고 처음부터 다시 만든다
의사코드로 쓰면 이런 느낌이다.
FUNCTION GenerateBoard(rows, cols)
REPEAT
board ← EMPTY 2D ARRAY [rows × cols]
FOR r ← 0 TO rows - 1 DO
FOR c ← 0 TO cols - 1 DO
board[r][c] ← RANDOM INTEGER IN [1, 9]
END FOR
END FOR
s ← SUM OF ALL ELEMENTS IN board
UNTIL s MOD 10 = 0
RETURN board
END FUNCTION
5. 정말 이 모델이 원본과 맞나
Rejection sampling 방식으로 보드를 10,000판 시뮬레이션해서 실제 데이터와 비교해봤다.
보드별 카이제곱 분포를 KS 검정으로 비교한 결과는 다음과 같았다.
| 검정 | D 통계량 | p-value | 결론 |
|---|---|---|---|
| 관측값 vs Rejection Sampling | 0.0335 | 0.65 | 차이 없음 |
p-value가 0.65이면, 적어도 이 데이터 기준에서는 두 분포가 다르다고 볼 근거가 없다. 즉, 실제 원본 보드와 이 모델이 아주 잘 맞는다는 뜻이다.
6. 직접 구현해보면
실제로는 아래 같은 코드로 바로 구현할 수 있다.
// TypeScript
function generateBoard(): number[][] {
const ROWS = 10, COLS = 17;
while (true) {
const board: number[][] = [];
let sum = 0;
for (let r = 0; r < ROWS; r++) {
board[r] = [];
for (let c = 0; c < COLS; c++) {
board[r][c] = Math.floor(Math.random() * 9) + 1;
sum += board[r][c];
}
}
if (sum % 10 === 0) return board;
}
}
이 방식으로 500판을 생성해서 원본과 다시 비교해본 결과도 큰 차이는 없었다.
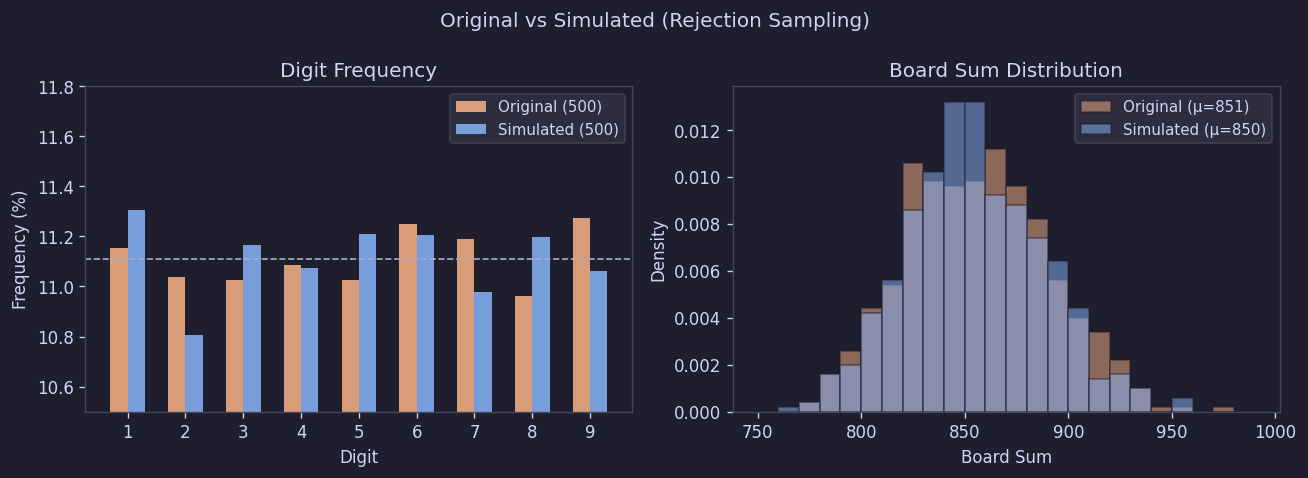
Figure 15. 원본 vs 생성 보드 비교
| 지표 | 원본 (500) | 생성 (500) | KS p-value |
|---|---|---|---|
| 합계 평균 | 851.3 | 849.9 | 0.56 |
| 판별 χ² 평균 | 8.22 | 8.08 | 0.82 |
즉, 숫자 구성, 총합 분포, 판별 편차 모두에서 생성 보드와 원본 보드가 사실상 구별되지 않았다.
7. 결론
500판을 분석해본 결과, 원본 사과게임의 보드 생성 방식은 rejection sampling으로 추정되며, 이 과정 외에 별도의 위치 규칙이나 사후 보정, 난이도 조절은 보이지 않았다.
이러한 추정을 바탕으로 우리는 다음과 같은 보드 생성 로직을 만들었다.
- 170칸 각각에 1~9 중 하나를 랜덤으로 넣는다
- 전체 합을 계산한다
- 합이 10의 배수이면 채택하고, 아니면 버리고 다시 만든다
우리가 구현한 방식으로 생성한 보드를 원본 데이터 500개와 비교 분석해 본 결과, 두 보드 데이터는 통계적으로 구별되지 않았다. 실제로 플레이했을 때 느껴지는 난이도 편차 역시 원작과 매우 비슷했다. 어떤 판은 이상하게 잘 풀리고, 어떤 판은 유독 어려운 그 부분까지 의도대로 원본과 똑같이 구현되었다.