オリジナルりんごゲームとの難易度の違い
2026年3月13日
要約
オリジナルのりんごゲーム(フルーツボックス)からスクリーンショットとOCRで500枚のボードを抽出し、生成アルゴリズムを統計的に分析した。合計85,000個の数字を検証した結果、各マスは1〜9の間で独立かつ均等に抽出されており、位置の偏り、隣接マスの相関、特定の数字への偏りなどのパターンは見られなかった。また、各ボードの全数字の合計はボードごとに異なり、すべて10の倍数であることを確認した。これらの結果から、オマージュ元であるオリジナルのりんごゲームはRejection Samplingでボードを生成していると推定し、これを実装して生成したボードはKS検定の結果、オリジナルデータと有意な差がなかった(p=0.65)。
一行まとめ: 私たちのりんごゲームのボード難易度は、オリジナルのりんごゲームと同じである。
1. はじめに
りんごゲーム(フルーツボックス)は、17×10のグリッドに1〜9の数字が配置され、合計が10になる長方形の領域を選んで消すパズルゲームである。シンプルながら中毒性のあるこのゲームを数百回プレイしていると、毎回難易度が異なり、ボード上の数字の分布によって決まることに気づく。一般的に大きな数字が多いほど難しくなる傾向があり、場合によっては最適に近いプレイでも非常に低いスコアしか得られないこともある。
極端な例を考えてみよう。
- 170マスすべてが9の場合、合計は1,530だが、どの組み合わせでも合計10を作れないためスコアは0点
- 逆にすべてが1の場合、合計は170で、どの10マスを選んでも合計が10になるため、ほぼ満点に近い回
実際のボードはもちろんこの両極端の間のどこかにある。それでも大きな数字(7、8、9)が多いと明らかに厳しくなり、小さな数字が多いと組み合わせを作りやすくなる。一定レベル以上のプレイヤーなら制限時間終了時に「見える」数字のペアはほぼ見つけているため、ボードの数字分布がスコアを決定する上で大きな役割を果たす。
派生ゲームの中には、これを「不公平」と見なして数字の分布を意図的に調整するものもある。しかし私は、この運の要素こそが原作の面白さの核心だと考えている。毎回難易度が少しずつ異なるからこそ緊張感が生まれ、難易度に応じた多様な戦略が可能になる。特に対戦の場合、このボードの運要素は大きな面白さとなる。良いボードで最高得点を出す人もいれば、厳しいボードから最大限のスコアを絞り出す人もいるため、勝負がより予測不可能で白熱したものになる。
ただし、オリジナルのゲームでは同じボードでプレイすることが不可能であり、そのためN回の平均で対戦するしかなかった。Nが十分に大きくないため、時には不快なほど運の要素が大きくなることもあり、それが同じボードで一緒にプレイできるこのゲームを作るきっかけとなった。オリジナルのように毎回ボードの難易度が変わる点は維持しつつ、同じボードでプレイするため「ボードの難易度を考慮した戦略」もゲームの一部となるようにしたかった。
したがって、「オリジナルとできるだけ同じ難易度分布を再現すること」は重要だった。より難しくもなく、より簡単でもなく。そこでオリジナルのゲームから500枚のボードを集め、どのような方式で生成されているかを分析した。
2. 方法
2.1 ボードの収集
Playwright(headless Chromium、2倍解像度)を使用してオリジナルサイトのプレイを自動化した。
接続 → Play → スクリーンショット → リロード
この過程を500回繰り返してボード画像を収集した。
2.2 OCRパイプライン
スクリーンショットから数字を読み取る過程は以下の順序で行った。
1. 緑の枠線検出 — HSV閾値でゲームフレームを検出する。

Figure 1. 緑の枠線検出結果
2. りんご領域のクロップ — 赤色のHSVマスクを使用してりんご領域のみを切り出す。

Figure 2. りんご領域のクロップ結果
3. グリッド整列 — 重心と1Dクラスタリングで10行×17列のグリッドを整列する。

Figure 3. グリッド整列(黄線:行/列の中心、緑点:各マスの中心)
4. マスごとのOCR — 各60×60 pxのマスを前処理した後、Tesseractで数字を読み取る。
使用した前処理:
- マージンクロップ(上17、下10、左右19 px)
- グレースケール → 閾値200 → 反転
- パディング15px → リサイズ128×128 → 閾値128
- Tesseract
--psm 6 --oem 1 -c tessedit_char_whitelist=123456789

60×60 cell→

Crop→

Gray→
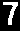
Thresh→
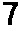
Invert→

Final→7

60×60 cell→

Crop→

Gray→

Thresh→
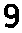
Invert→

Final→9

60×60 cell→

Crop→

Gray→
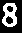
Thresh→
Invert→

Final→8
Figure 4. マスごとのOCR前処理例
2.3 データ整合性の検証
2.3.1 チェックサム検証
各ボードは170個の数字($d_i \in \{1, \dots, 9\}$)で構成され、ゲームのルール上、合計は10の倍数でなければならない。
$$\sum_{i=1}^{170} d_i \equiv 0 \pmod{10}$$つまり、OCRに誤りがあればこの条件を破る可能性が高い。誤りがランダムな置換だと仮定すると、誤りがあるのに偶然チェックサムを通過する確率はおよそ1/10である。
$$P_{\text{false\_pass}} \approx \frac{1}{10}$$結果として、500枚のボードすべてがチェックサムを通過した。
2.3.2 手動検証
複数の誤りが互いに相殺してチェックサムを偶然通過するケースを検出するため、全体の5%にあたる25枚のボードを実際にスクリーンショットと目視で照合した。検査した数字は合計4,250桁(170 × 25)で、誤りは0件だった。
$n$回の検査で誤りが1つも見つからなかった場合、誤り率$p$の95%信頼上限はRule of Threeで以下のように推定できる。
$$p \le \frac{3}{n} = \frac{3}{25} = 0.12 \quad (12\%)$$2.3.3 総合信頼度
2つの検証方法は独立であり、したがって未検出の誤りの結合確率は以下の通りである。
$$P_{\text{undetected}} = p \times P_{\text{false\_pass}} \approx 0.12 \times 0.1 = 0.012 \quad (1.2\%)$$つまり、データセットの統計的信頼度は98.8%であり、OCR処理が適切に行われたと言える。
3. 実際にどのようなパターンが見られたか
3.1 数字の頻度はほぼ完全に均等だった
500回分、合計85,000個の数字を数えたところ、1〜9はほぼ同じ割合で出現した。
| 数字 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 回数 | 9,479 | 9,381 | 9,373 | 9,422 | 9,371 | 9,562 | 9,512 | 9,319 | 9,581 |
| % | 11.15 | 11.04 | 11.03 | 11.08 | 11.02 | 11.25 | 11.19 | 10.96 | 11.27 |
| 均等分布 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 | 11.11 |
カイ二乗検定の結果もchi-sq = 7.30、p = 0.504だった。つまり、「各数字が同じ確率で出現する」という仮説をまったく棄却できなかった。
これは非常に重要である。少なくとも全体の数字分布を意図的に調整した痕跡は見られないことを意味するからだ。
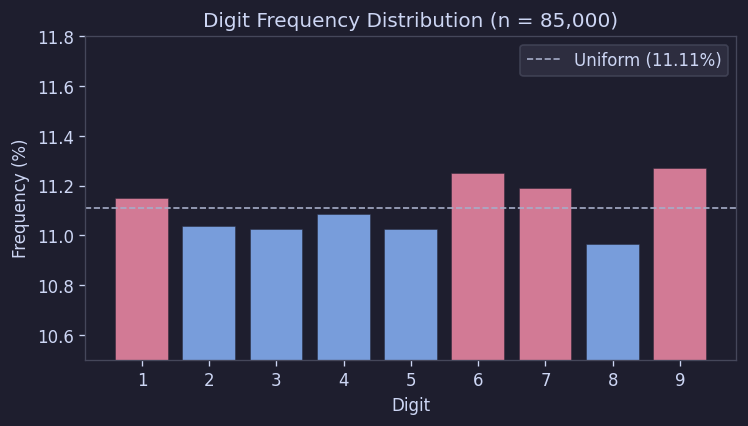
Figure 5. 数字別出現頻度
3.2 ボード合計も理論値とよく一致した
170マスを1〜9の均等分布から独立に抽出する場合、ボード合計の理論的な平均は850、標準偏差は約33.7である。
実際の観測値は平均851.3、標準偏差34.8だった。
この程度であれば理論とほぼ同じ水準である。つまり、合計分布だけを見ても「基本的には均等な乱数170個を抽出している」という解釈とよく一致する。
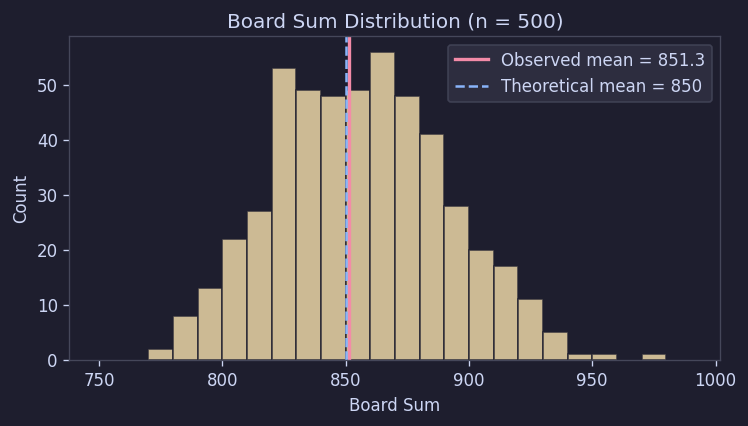
Figure 6. ボード合計の分布
3.3 特定の位置に特定の数字が偏ることはなかった
ある位置に大きな数字がより頻繁に出現したり、端と中央で異なるルールがあるかもしれない。そこでマスごとの平均値を確認した。
結果は非常にシンプルだった。500回の平均で、すべてのマスがほぼ5.0付近に集まり、行平均は[4.97, 5.04]、列平均は[4.92, 5.07]の範囲だった。
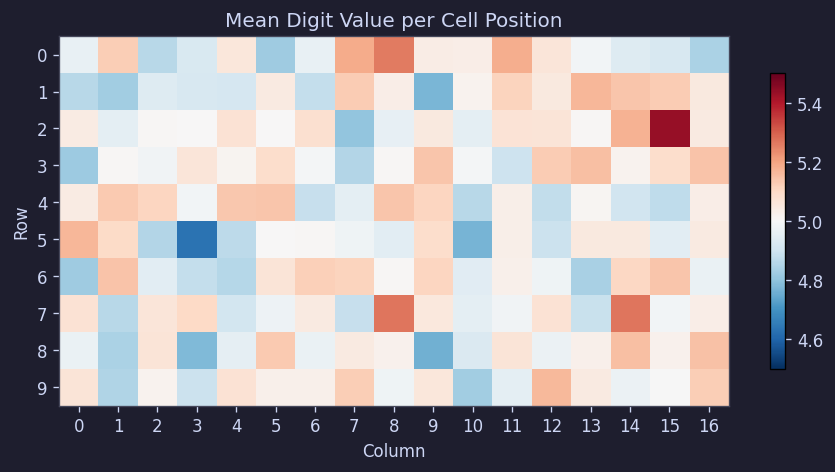
Figure 7. マスごとの平均数字ヒートマップ
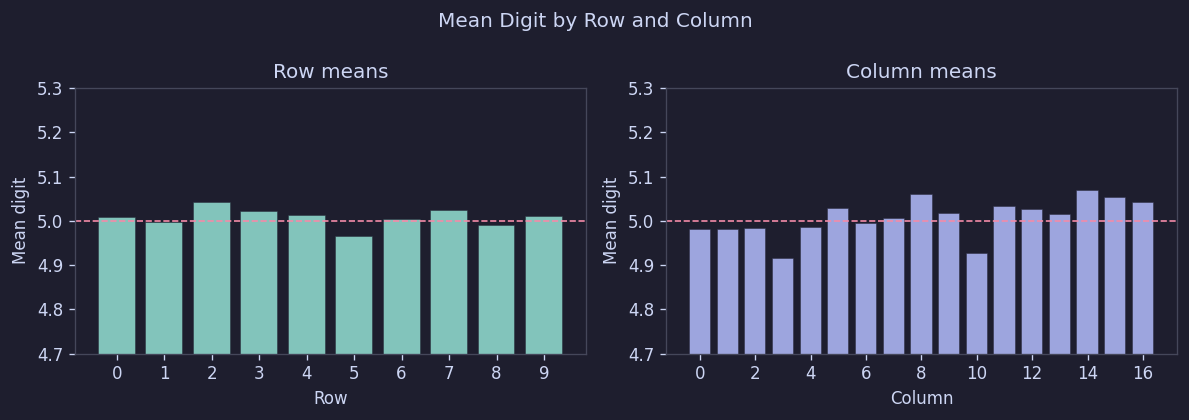
Figure 8. 行/列別の平均数字
つまり、位置による偏りは見られなかった。少なくとも「上の行は簡単にする」「中央に大きな数字を多く配置する」といった構造は存在しない。
3.4 全体は均等だが、個々のボードはかなりばらつく
ここで興味深いのは、全体としては完全に均等に見えても、個々のボード単位で見るとかなり不均衡なものが多いという点である。9が異常に多いボードもあれば、1や2が比較的多いボードもある。プレイ中に感じる「今回なんでこんなに難しいんだ」が、実際にデータにも表れているということだ。
これを数値で確認するため、各ボードの数字構成と期待値(各数字あたり18.89個)を比較してカイ二乗値を計算した。独立均等分布であればこの値はchi-sq(df = 8)に従うはずである。
| 観測値 (500) | Rejection Sampling (10,000 sim) | chi-sq(df=8) 理論値 | |
|---|---|---|---|
| 平均 | 8.22 | 7.99 | 8.00 |
| 中央値 | 7.46 | 7.35 | 6.34 |
| 標準偏差 | 4.17 | 3.94 | 4.00 |
観測値は理論値とよく一致し、シミュレーション結果ともほぼ重なった。つまり、「個々のボードがばらつくこと」自体がむしろ自然な現象である。意図的に難易度を調整した痕跡ではなく、もともとランダム生成であれば当然出るはずの変動性に近い。
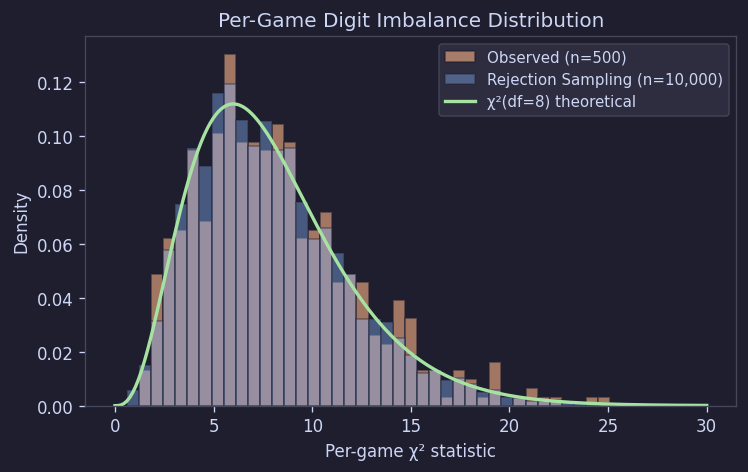
Figure 9. ボードごとのカイ二乗分布(観測 vs シミュレーション vs 理論)
Q-Qプロットでも確認できる:
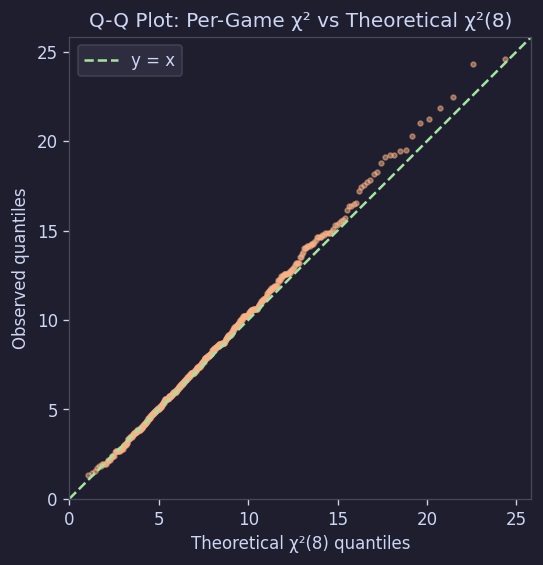
Figure 10. Q-Qプロット:ボードごとのchi-sq vs 理論的chi-sq(8)
最大偏差と不足/過剰パターン
各ボードで期待値から最も大きく外れた数字の偏差を見ても、シミュレーションとよく一致した:
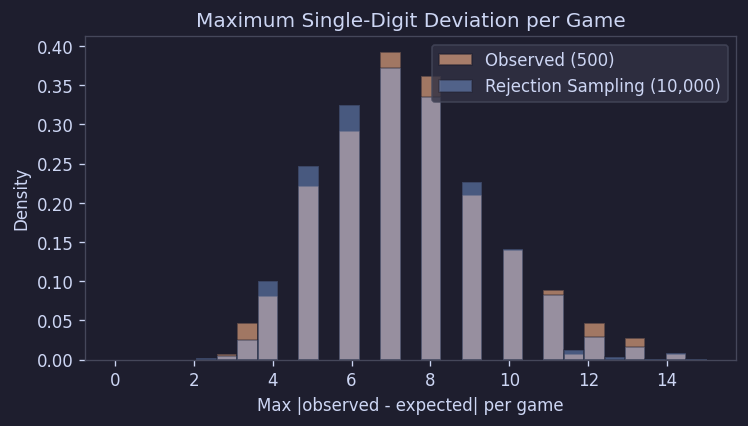
Figure 11. ボードごとの最大偏差分布
「最も多く出現した数字」や「最も少なく出現した数字」を数えても、特定の数字への偏りはなかった:
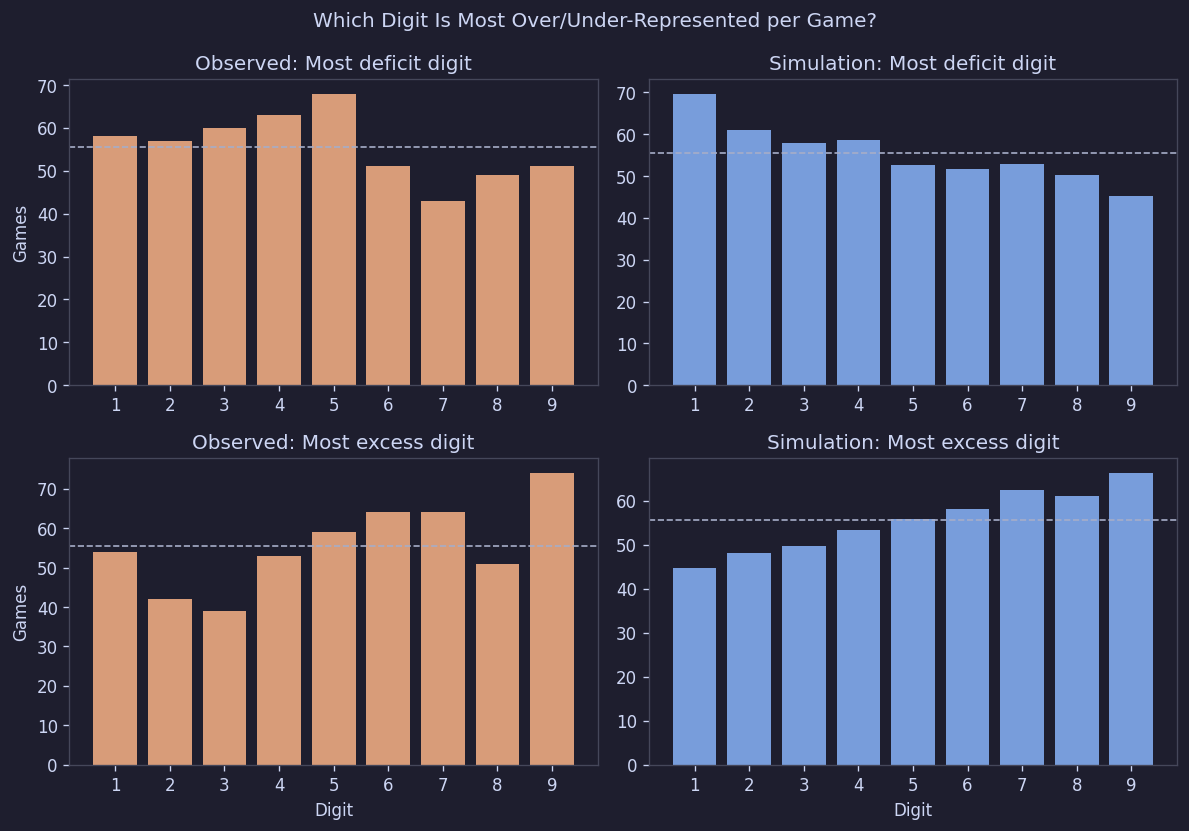
Figure 12. ボードごとの不足/過剰数字パターン
簡単に言えば、ある数字が頻繁に過剰になったり頻繁に不足したりする構造はなかった。
3.5 隣接マス同士も事実上独立だった
数字が完全に独立ではなく、隣のマスとある程度関連している可能性もある。たとえば、似た数字同士が固まったり、小さい数字の次に大きい数字が出やすいといったパターンだ。
そこで隣接マスの相関を計算した。
| 方向 | n | Pearson r | p-value |
|---|---|---|---|
| 水平 | 80,000 | 0.0007 | 0.853 |
| 垂直 | 76,500 | -0.0012 | 0.730 |
結果はどちらもほぼ0だった。
遷移行列(数字iの後に数字jが出る確率)も期待値11.1%から±0.5ポイント以内だった:
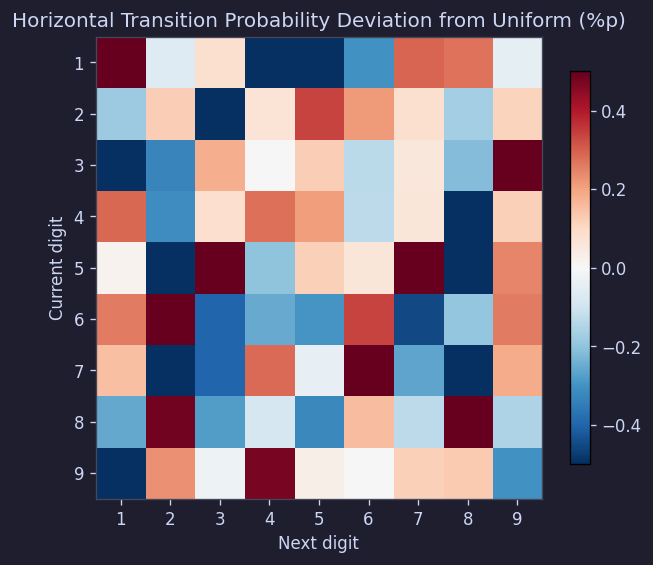
Figure 13. 水平遷移確率偏差行列
自己相関もすべてのラグで95%信頼区間内に収まった:
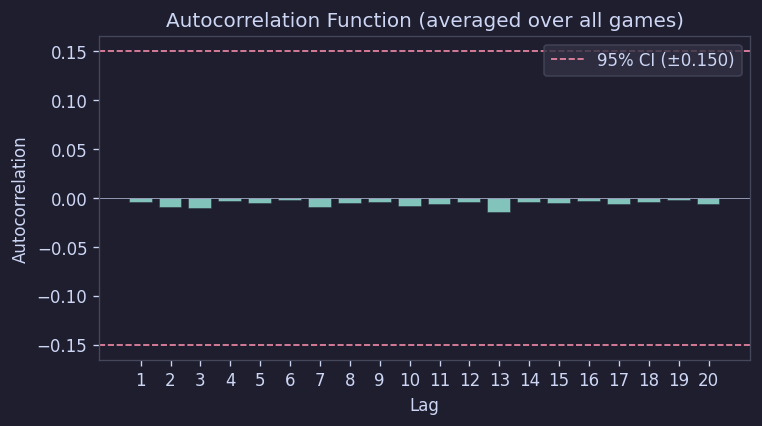
Figure 14. 自己相関関数
つまり、数字は隣接するマスとも特別な関係なく配置されていると見るのが妥当である。
4. では生成アルゴリズムは何か
これまでの結果を整理すると以下の通りである。
- 各マスの数字は1〜9の間で均等に出現する
- マス間に特別な相関はない
- 位置による偏りもない
- ただし全体の合計は必ず10の倍数でなければならない
これらの条件を最もシンプルに満たす方法は実はひとつだけである。それがRejection Samplingだ。
つまり、
- まず170マスすべてに数字をランダムに入れる
- 合計を計算する
- 合計が10の倍数なら採用する
- そうでなければ破棄して最初からやり直す
擬似コードで書くとこのようになる。
FUNCTION GenerateBoard(rows, cols)
REPEAT
board ← EMPTY 2D ARRAY [rows x cols]
FOR r ← 0 TO rows - 1 DO
FOR c ← 0 TO cols - 1 DO
board[r][c] ← RANDOM INTEGER IN [1, 9]
END FOR
END FOR
s ← SUM OF ALL ELEMENTS IN board
UNTIL s MOD 10 = 0
RETURN board
END FUNCTION
5. このモデルは本当にオリジナルと一致するのか
Rejection Sampling方式でボードを10,000回シミュレーションし、実際のデータと比較した。
ボードごとのカイ二乗分布をKS検定で比較した結果は以下の通りだった。
| 検定 | D統計量 | p-value | 結論 |
|---|---|---|---|
| 観測値 vs Rejection Sampling | 0.0335 | 0.65 | 差なし |
p-valueが0.65であれば、少なくともこのデータに基づく限り、2つの分布が異なると判断する根拠はない。つまり、実際のオリジナルボードとこのモデルが非常によく一致しているということだ。
6. 実装してみると
実際には以下のようなコードで直接実装できる。
// TypeScript
function generateBoard(): number[][] {
const ROWS = 10, COLS = 17;
while (true) {
const board: number[][] = [];
let sum = 0;
for (let r = 0; r < ROWS; r++) {
board[r] = [];
for (let c = 0; c < COLS; c++) {
board[r][c] = Math.floor(Math.random() * 9) + 1;
sum += board[r][c];
}
}
if (sum % 10 === 0) return board;
}
}
この方式で500回生成したボードをオリジナルと再度比較した結果も、大きな差はなかった。
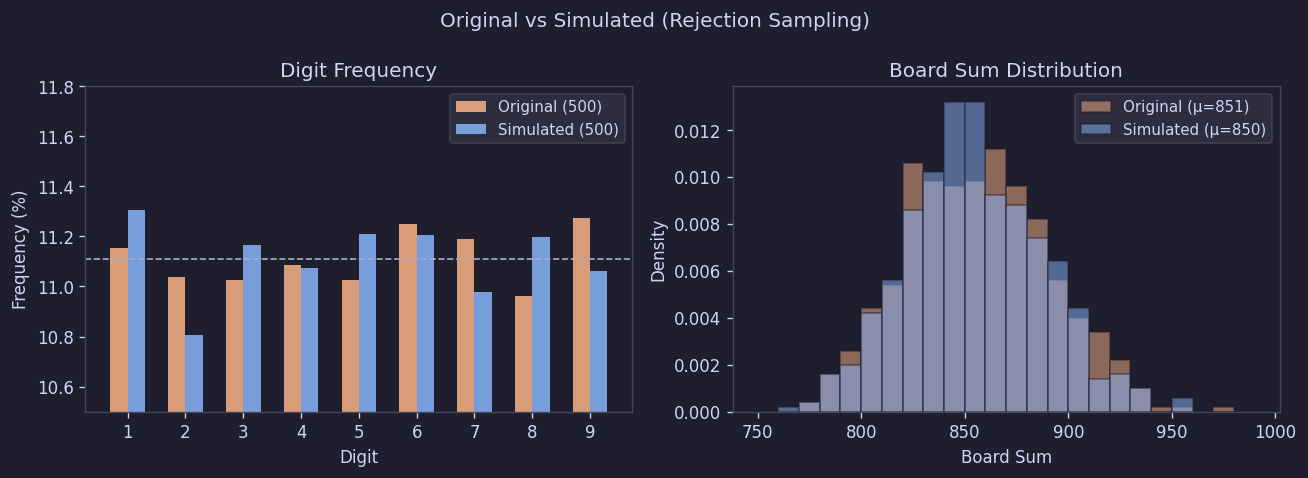
Figure 15. オリジナル vs 生成ボードの比較
| 指標 | オリジナル (500) | 生成 (500) | KS p-value |
|---|---|---|---|
| 合計平均 | 851.3 | 849.9 | 0.56 |
| ボードごとのchi-sq平均 | 8.22 | 8.08 | 0.82 |
つまり、数字の構成、合計の分布、ボードごとの偏差すべてにおいて、生成ボードとオリジナルボードは事実上区別できなかった。
7. 結論
500回分のボードを分析した結果、オリジナルのりんごゲームのボード生成方式はRejection Samplingと推定され、それ以外の位置ルール、事後補正、難易度調整は見られなかった。
この推定に基づき、私たちは以下のようなボード生成ロジックを作成した。
- 170マスそれぞれに1〜9のいずれかの数字をランダムに入れる
- 全体の合計を計算する
- 合計が10の倍数であれば採用し、そうでなければ破棄して再生成する
私たちが実装した方式で生成したボードをオリジナルデータ500枚と比較分析した結果、2つのボードデータは統計的に区別できなかった。実際にプレイした際に感じる難易度のばらつきもオリジナルと非常に似ていた。ある回は不思議なほどうまくいき、ある回は特に難しい — その部分まで意図した通りにオリジナルと同じように再現された。